AWS Step Functions in service of MLOps, and more
Learn how AWS Step Functions can help you orchestrate machine learning operations and how it stacks up against SageMaker Pipelines.
 AWS Step Functions
AWS Step Functions Amazon SageMaker
Amazon SageMaker

This is the second of four articles concerning machine learning orchestration at AWS. We already briefly talked about serverless orchestration, highlighting the three main AWS services in that category and describing one of them — SageMaker Pipelines. We also introduced SageMaker and briefly spoke about data science and MLOps in general. Familiarity with those concepts is recommended.
Before we proceed to review AWS Step Functions, we will first familiarize you with yet another important topic which emerged lately in the machine learning community: data-centric AI.
What is data-centric AI?
Real-world data science projects rarely follow the happy path described in most articles. The curated datasets used in those tutorials and courses are nothing like the ones you will see in reality. Even a small sized company has a number of internal systems. Each of them stores different pieces of data you need to analyze. Some are brand-new services with well-designed databases. Some are SaaS-only, with an API and no access to raw data. Some are legacy monoliths and the only person that truly knew the ins and outs of the system just left the company. And so on. The consistency, availability and freshness of this data also varies.
Data warehouses, lakes, marts, meshes — or whatever we call them this year — promise to solve this issue by storing data in one place (or at least to have it grouped by business domain), providing data catalogs, data lineage systems, testing it and generally improving its quality and overall reliability. They definitely make the lives of data scientists easier.
However, deploying such a solution is a cumbersome and lengthy process, and most importantly gives little benefit on its own. Unless there is a specific, tangible use case based on it, it might be hard to convince the company that they actually need it. After all, their existing business intelligence tools get by with no data lakes yet generate useful insights every day. And they would require a general refactoring afterward!
Those problems also caused the birth of a data-centric AI movement which gains traction daily. In a way, the final result you get from a model is already bounded by the quality of your data. The output can get only as good as the data you provide. Thus, we should encourage everybody, even with no machine learning expertise, to take care of the data that the systems they use and store.
For a medical doctor, it is a trivial task to point out what is actually important in their patients’ data. That insight, passed over to a data engineer can in turn result in a huge boost of accuracy in various machine learning projects based on that dataset. Data lakes would not be that important if every system had a top-notch quality dataset.
Also, training the model on your data is a solved problem and the process of spinning up a cluster of machines to find a suitable algorithm by crunching some numbers can be fully automated. Solutions like SageMaker Autopilot (“just put the data in and get great results out”) do exactly this… but their main premise is that the data is a curated dataset with a cherry on the top. Ask a data scientist how much they spend on model building, and they will just nervously laugh and mumble something inaudible about “feature engineering”.
Prerequisites and dependencies
Unfortunately, the utopian world described above (data stored inside meshes and everybody ensuring that its quality is top-notch) rarely exists. Thus, our machine learning pipeline will spend a lot of its time outside the machine learning ecosystem. Model building parts of the pipeline may use a lot of machines and take a lot of their CPUs and GPUs, but are rather straightforward to implement.
Various data engineering tasks have to be performed as a necessity for the machine learning pipeline. Merging and curating datasets also requires large clusters but with different technologies running inside. Additionally, the birth of a machine learning model’s version is usually not the end of the pipeline in a business context. Reports and insights have to be generated, people and other business processes have to be notified and the endpoint has to be redeployed.
There is quite a lot happening both before and after the model building pipeline. Unfortunately, the previously described SageMaker Pipelines offer little connection with AWS services outside SageMaker. Spinning a Lambda is not always desired as the less code the better. Surely there must be a service with a broader spectrum of integrations… and indeed there is:
AWS Step Functions as a ML orchestrator
On a basic level, AWS Step Functions are similar to Amazon SageMaker Pipelines. You split the workload into smaller logical pieces and then define what needs to be done in what order. Step Functions can be used to orchestrate it, i.e. handle the actual execution of every step.
However, Step Functions are way more sophisticated than SageMaker Pipelines.
First of all, Step Functions natively integrate with many AWS services. They can be used to spin up Glue Jobs, operate EMR clusters, query DynamoDB, fire Lambdas, push messages to SQS or SNS, control various SageMaker tasks and many others. This allows you to build workflows tied not only to SageMaker, but to all important AWS data goodies you probably use as part of your business processes.
As of 30 September 2021 it also supports executing AWS SDK calls. So, if there is no native integration with some services, you can quite easily create one by calling AWS’ API. Previously, you had to code dumb-Lambdas to perform those calls. Sweet.
More complex parallelization patterns (such as creating separate branches) are available. You can also catch and handle errors and automatically retry the workflow if you desire so.
Additionally, Step Functions can also orchestrate other Step Functions. That means, your workflow can be split into two or more lesser workflows that are orchestrated by yet another meta-workflow. Imagine having a big piece doing a lot of black magic like this one:
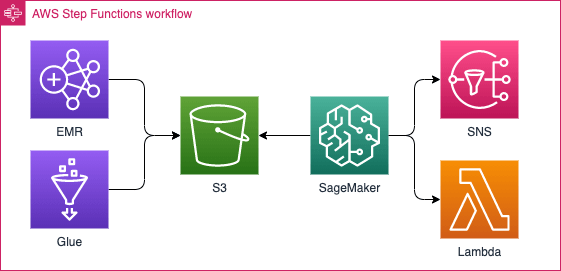
Of course, in reality, each of the pictograms consists of several complicated steps. That makes up for a very long, unmaintainable and hard to develop workflow. You can compare it to a method that has hundreds or thousands of lines of code. However, just like in programming, you can split it into smaller, tamable pieces of work and give each team their own black box of responsibilities:
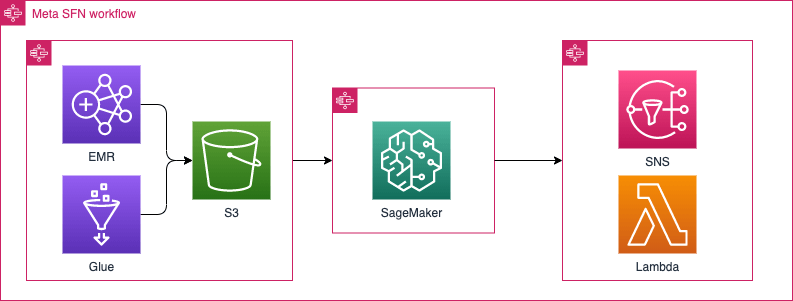
If you specify the contracts between each of those smaller workflows correctly (what do they take as an input and what is their result) then this can work very well. This is similar to integrating the APIs of various services.
Additionally, Step Functions are marketed as a low-code tool. Step Functions Workflow Studio was recently released and allows you to build workflows using a friendly GUI. In general, we are not huge fans of clicking around AWS Console, but Workflow Studio does not actually create your pipeline. It only creates prototype-ish source code filled with placeholders of your tasks. You then take the code back to your IDE, modify it and use it with your IaC tool of choice.
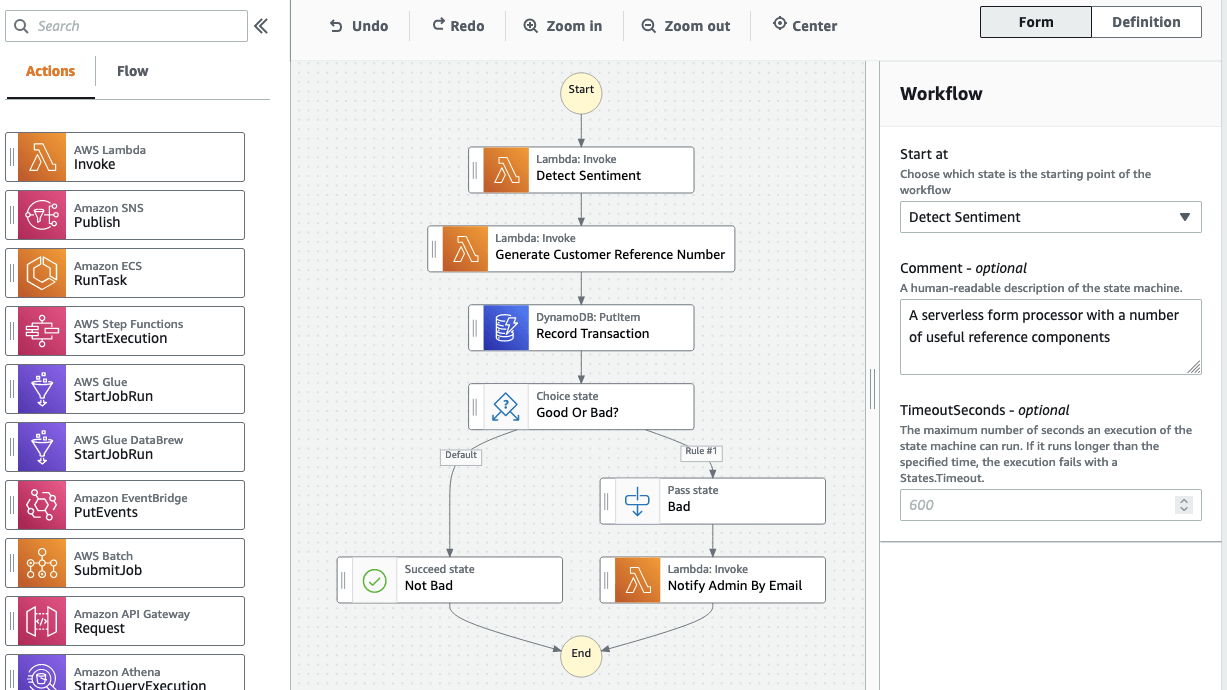
There are plenty of infrastructure as code choices. The most logical approach for a data science team would be the Step Functions Data Science SDK. You wire SageMaker SDK objects (like Estimators) using the Step Functions’ library, whose API closely resembles the one used in SageMaker Pipelines. Most features you need are available out of the box and extending this (tiny) library is straightforward. If the only people working on the orchestrator are machine learning engineers and data scientists, then this should probably be your first pick.
Additionally, AWS CDK support is available and Step Functions are L2 constructs there, i.e. they have a native CDK API — working with them should be a breeze. In general, AWS CDK is a versatile framework and your entire system can be written in it, making it a tool for everybody. If your team and system are large and a lot of people with different roles will be working on it, then having just one IaC tool will be handy.
Previous tools had a specialised, convenient API to build your workflows by using some kind of builder pattern. Others — such as Terraform, Pulumi, SAM, CloudFormation or Serverless Framework — also support SFN, but have no handy API. Pipeline code is imported from JSON or YAML files. This is slightly harder to develop and more error-prone with no IDE support. That said, you are able to use the GUI to generate that file for you and just fill the missing parts.
Lastly, one of SFN’s major features is its capability to process the input and output of each task with JSONPath syntax. Your pipeline execution may hold a large JSON containing the entire state, but each task needs just a tiny fragment of it. In Step Functions, you can freely select the portion you need at each step as well as change input parameter names. You can also filter the output of each step — e.g. running an AWS SDK integration results in a huge JSON response, but you might be interested only in a subset of it or even a single field (like an ARN of resource you just created). And, since these features and their syntax may be intimidating, there is a Step Functions Data Flow Simulator available in the AWS Console:
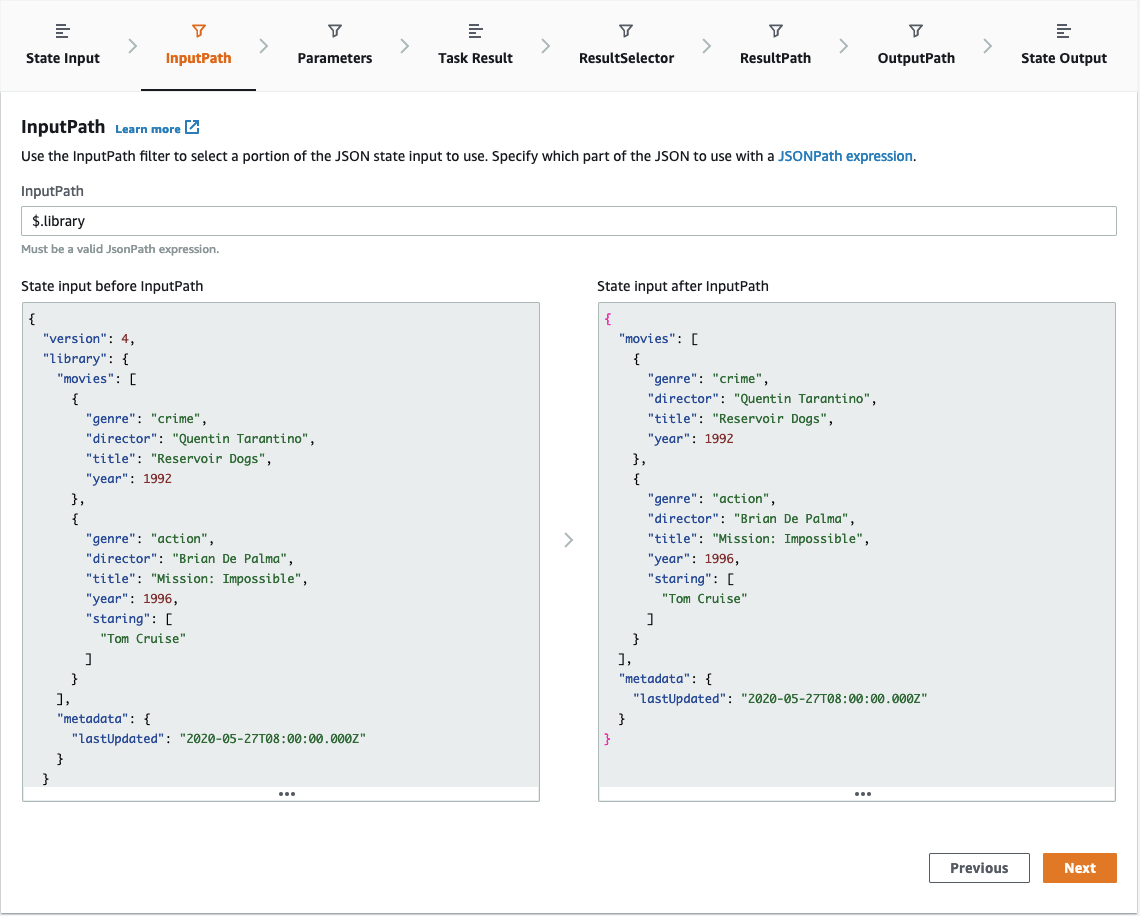
You may freely prototype and test more complicated scenarios of passing parameters in and out of the tasks with an instant feedback loop.
There are also Express Workflows, but due to their hard execution time limit of 5 minutes, they have limited use in machine learning. You can browse the difference between Standard Workflows and Express Workflows more closely here.
Pros of Step Functions for machine learning
Generally speaking, this is a mature and well-thought-out technology, used widely in lots of contexts. You will easily find learning resources and find somebody to help with your struggles. They also add new features several times a year.
SageMaker is a first-class citizen and, unlike SageMaker Pipelines, it can also handle deployment and redeployment of your SageMaker Inference Endpoint. That means, you are able to code your entire pipeline using one tool. This may or may not be feasible - SageMaker Pipelines deliberately finish when a new version of the model is ready, because they assume that another team (with their own specialised tools) should handle the next parts of the workflow, namely the deployment. But as shown above, you can split the responsibilities between many teams and give each of them their own tiny Step Function to create. Using the same tool in all those teams can speed up your overall development time. Usually the more people familiar with a given tool, the better.
Native integrations with the most important AWS services (not only SageMaker) and features such as Map or Input/Output processing enables you to create way more versatile and complex pipelines than in other tools. You would not be able to create them using SageMaker Pipelines or CodePipeline. Yet again, this may and may not be good news for you.
Last but not least, they originated as a tool for DevOps or Software Engineers. This might sound trivial or straight dumb but people could be less afraid of them, as there’s no “machine learning” in every sentence of their documentation. This might be a crucial argument if you just formed a data science team and everything is fresh and scary. You may also have a handful of people in your organisation that already used them in other contexts. And the knowledge they will acquire can be transferred to other teams, not necessarily ones doing data science.
Finally, in machine learning applications, they are cheap (but then, all the orchestrating technologies mentioned in our series are) . You don’t pay for execution time but only for every state change. Do note that you might find some resources telling you that Step Functions are expensive. They are indeed right. If you wanted to handle millions of e-commerce orders every day with them, then the associated cost would rack up rapidly. However, in our data science case, the cost is negligible, as you usually don’t run hundreds of thousands of concurrent executions per day.
Cons of Step Functions for machine learning
Step Functions are powerful and consist of many functionalities. Getting to know how input and output processing actually works, learning to differentiate between single and double dollar signs, deciding whether an asynchronous or synchronous job should be used and similar problems may be nontrivial matters at the beginning of your journey. The learning curve is slightly steeper than the one in SageMaker Pipelines.
As mentioned, retry and exception catching is available. It is however limited - you can only set your retry rules before executing the pipeline. When it runs and then unexpectedly blows up and an exception is not handled, you cannot just fix the broken task and pick up where you left off. You have to restart the entire pipeline. Step caching is not available so you may have to perform (already done) preprocessing again.
As the Step Function grows, it is getting harder and harder to test and develop it locally. There is an AWS Step Functions Local Docker image which theoretically helps, but the internet lacks good resources except for a few hello world-ish examples. Well, even if you actually ran a local version of SFN, mixing it with external Lambdas, SageMaker and others give you very little benefit. Thus, the development loop may be slow and cumbersome and IDE won’t help you much. You should definitely split your workflow into smaller ones as soon as possible. You will thank yourself for it later.
Additionally, some functionalities you’d expect SFN to have are missing. While loops — a standard tool (“wait until something is done”) — are unavailable, and you have to code it yourself with Lambdas and cycles in the graph. For loops are theoretically available as Map state, but it does not always cover all use cases, and you might also have to program it yourself. AWS Step Functions Data Science SDK is missing some integrations. At the time of writing, running another SFN execution isn’t possible yet, and you have to extend the library yourself (which is easy but requires coding). Fortunately, the CDK covers that.
SageMaker Pipelines vs Step Functions
In our previous article about SageMaker Pipelies, we made a pretty bold statement suggesting that whenever you’re in SageMaker, you should pretty much always use the SageMaker Pipelines. Yet, when comparing even solely SageMaker integration capabilities of both technologies, one may say that their functionalities overlap, and thus you should pick the one more versatile.
Instead, We suggest basing your approach on the roles in your team . If your team consists of only data scientists and DevOps engineers, then SageMaker Pipelines with SageMaker Projects should be a perfect match. Data scientists will create a well-designed blackbox with their algorithms, which will then be used by the ops team as a part of their usual deployment pipeline (written in Terraform, CDK or CloudFormation and paired with Jenkins, CodePipeline, CircleCI, GitLab CI or whatever other tools they use in their daily work). You will not add any new tools to either of the teams. Data scientists will keep using their usual SageMaker library and DevOps engineers will keep using their IaC of choice. Everybody will remain productive and happily run production-ready workflows.
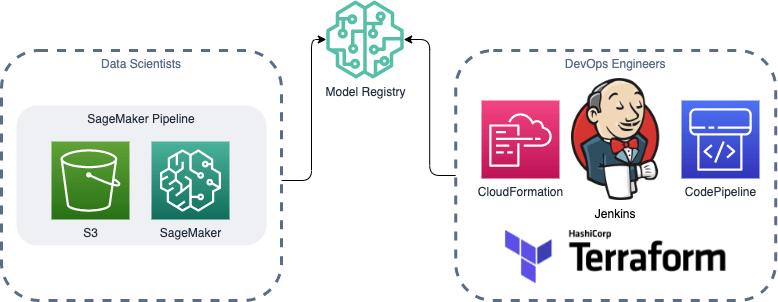
On the other hand, if your team consists of more roles, such as for example data engineers and machine learning engineers too, then you will most likely need to introduce Step Functions. Every role has to add their parts to the overall workflow, and you will have one tool to rule it all:
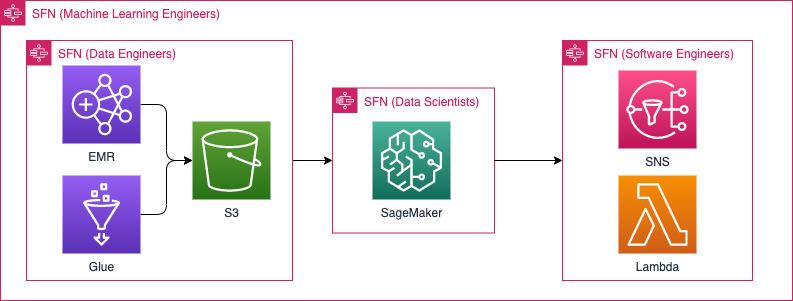
When your pipeline consists of not only SageMaker but also other AWS tools — such as Glue, EMR or ECS — and you juggle between them back and forth, Step Functions will have you covered in most cases — unlike SageMaker Pipelines.
Note that the approach above assumes that you heavily use SageMaker. This is not always the case — your company did not necessarily go all in on AWS. Perhaps all you wanted to do is utilise its elastic compute. You may only run custom containers on ECS or Batch and serve them behind API Gateway. Basically, if you’re not inside SageMaker yet (after all SageMaker is not the only machine learning platform available). In that case, Step Functions are also a perfect solution to schedule your containers.
Lastly, even if you are mostly in SageMaker, but your workflow is very complex and consists of dozens or hundreds of steps, then additional capabilities of Step Functions over SageMaker Pipelines (such as splitting your workflow into smaller Step Functions, utilising for and while “loops” or doing some complicated input/output processing) might play a crucial role.
Beyond machine learning orchestration
Even though our series concerns mostly data science use cases, you should note that Step Functions are not only used in machine learning systems. Most resources you find will actually not touch ML.
First, Step Functions are usually the main building block of general purpose serverless applications. They model business interactions happening between various components of the system. Chaining Lambda calls or implementing failure handling with the saga pattern is straightforward in AWS Step Functions, especially given its native integrations with the bread and butter of serverless development: API Gateway, DynamoDB or SQS. Amazon gives many examples of SFN usage, such as bucket flights reservations, cart checkouts or payments through external APIs.
Additionally, other workflows can also emerge in Step Functions — not only those tied to machine learning. Any DevOps task is usually a playbook consisting of several dependent and interconnected steps. Database migration or controlled failover, S3 bucket migrations, controlled replacement of EC2 machines and similar. This is especially worth implementing if such processes span across multiple accounts, regions and are generally error-prone and critical to the underlying business. Step Functions will let you code error handling, retrying and all the custom logic with ease.
Finally, they are often used in data engineering to orchestrate your ETL pipelines. As mentioned previously, there are dozens if not hundreds of integrations available with Amazon EMR, Glue, Glue DataBrew and Batch among them. Data engineering does not necessarily automatically imply some machine learning magic afterward. You don’t need Amazon SageMaker!
AWS Step Functions…
- Is a tool for everybody — data scientists, data engineers, DevOps engineers or software engineers;
- Can orchestrate the entire machine learning workflow, not just model building;
- Can be used as an “orchestrator of orchestrators”, i.e. can manage other SFN pipelines — splitting your workflow into smaller ones is a great idea;
- May be overwhelming if the data science team is SageMaker-heavy and has no machine learning engineers;
- Has more advanced capabilities like parallelizing jobs, retrying, exception handling, filtering input data between tasks;
- Integrates seamlessly with most AWS data related tools and also AWS SDK itself;
- Is rather cheap;
- Might be hard to develop — has a learning curve, local development is tough.
