Simplify AWS ECS Task definition versioning
Practical tips for semantic versioning, IaC and other DevOps best practices based on Apache Airflow (AWS MWAA) containers on ECS.
 Amazon Elastic Container Service
Amazon Elastic Container Service Amazon Managed Workflows for Apache Airflow
Amazon Managed Workflows for Apache Airflow Apache Airflow
Apache Airflow Database Build Tool
Database Build Tool


Anyone using Amazon ECS and infrastructure as code tools of any kind — such as Terraform, CDK or Pulumi — will inevitably face a subtle issue: how to make the ever-changing Task definition revisions and container image versions stay reliably in sync with IaC code, which itself is also versioned. To complicate things, any proper solution needs to be viable for multiple environments.
In this article, we’ll focus on solving a relatively common issue in cloud-native data engineering projects: with Apache Airflow (AWS MWAA) running dbt containers scheduled by AWS ECS, how can we take care of semantic versioning, IaC and all the best DevOps practices in a sane way?
The problem
Amazon ECS is a container orchestration service. You instruct it to run a given container and it will handle the heavy lifting for you — find an appropriate compute environment and then run & manage the container’s lifecycle.
The service also handles load balancing, autoscaling, smooth deployment, service discovery, logging and more (by itself or by natively integrating with other AWS services that provide these features). ECS is comparable to technologies such as Kubernetes, Marathon or Nomad.
ECS can pull images from various sources, including public Docker registries or AWS ECR — a technology that simply stores your container images in AWS.
The basic, simplified flow (which skips things like ECS Agents or ECS Services, as those are irrelevant to this article) looks like below:
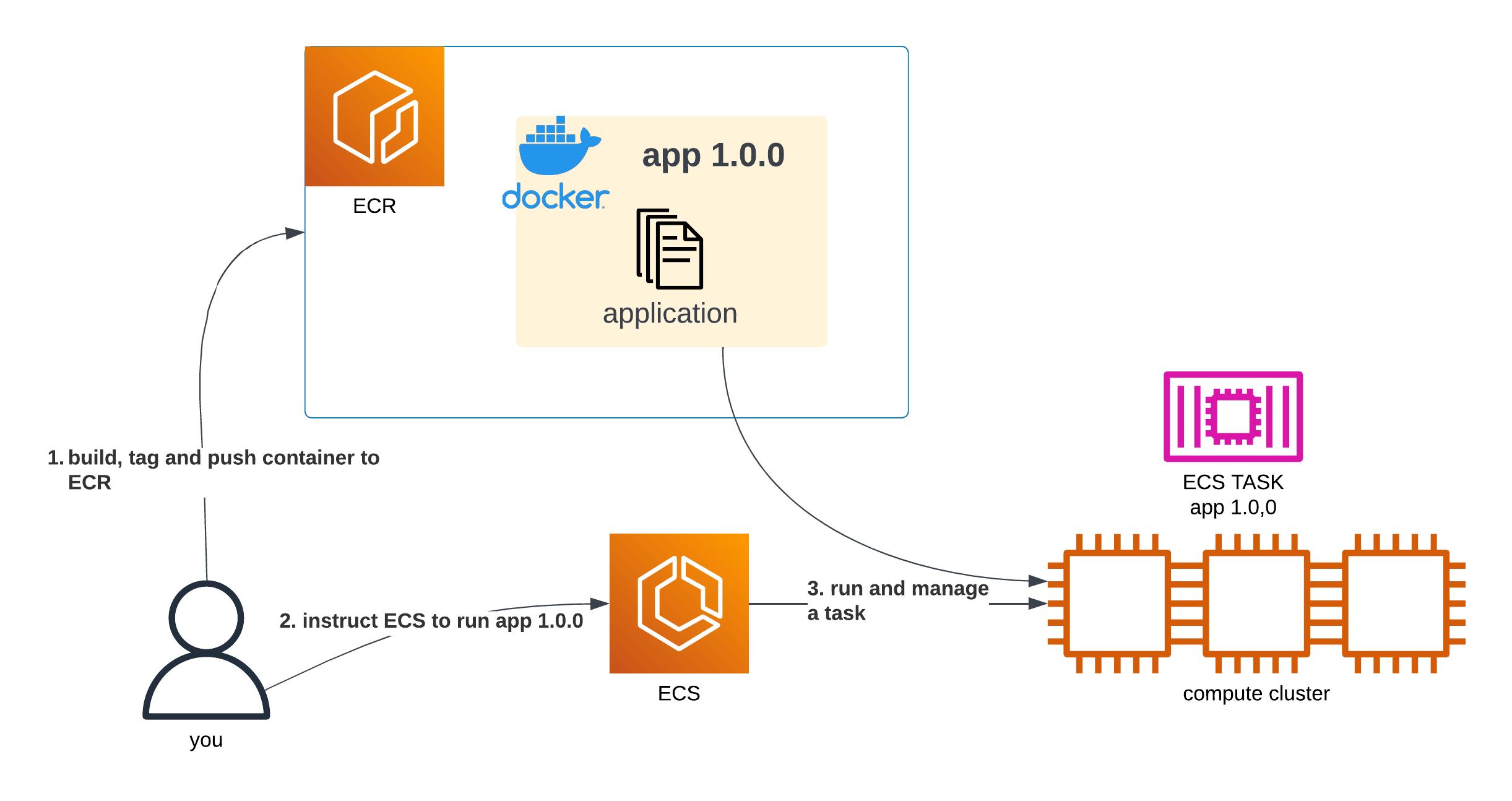
A diagram showing a user build a container, push it to ECR, instruct ECS to run it and ECS does so
We can simply tell ECS to run our app at tag 1.0.0, and it will do so.
Let’s assume some time passed by and a new version of our app has just been developed. Using the same approach, we could simply tell ECS to run the newest version of our app (the 1.1.0 tag):
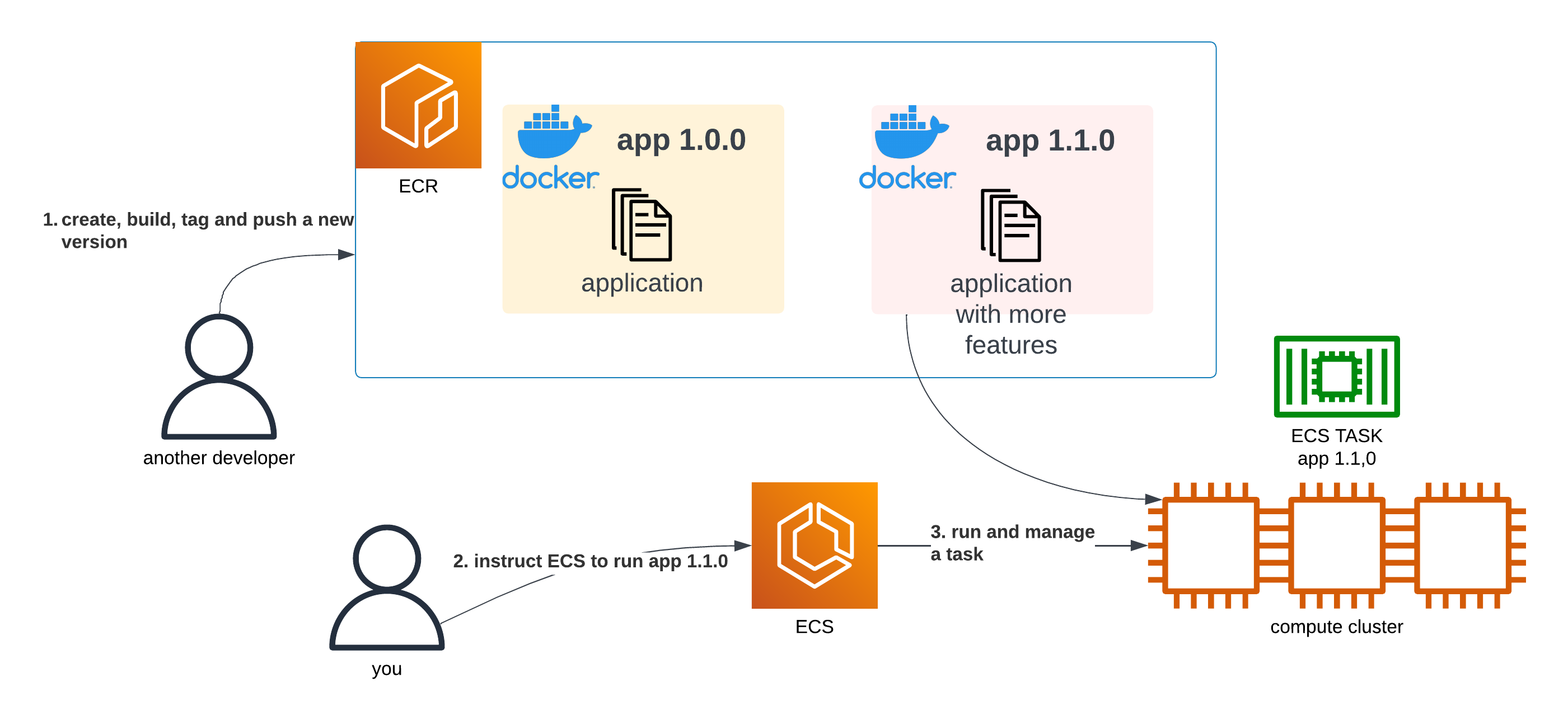
A diagram showing a user build a new version of a container, push it to ECR, instruct ECS to run the new version and ECS does so
If the ECS Task had been running continuously (like a web server that’s on 24/7), then ECS would also smoothly replace the previous version of the application (1.0.0) with the new one (1.1.0), without any impact on our ability to handle incoming requests. This is also known as a blue-green deployment:
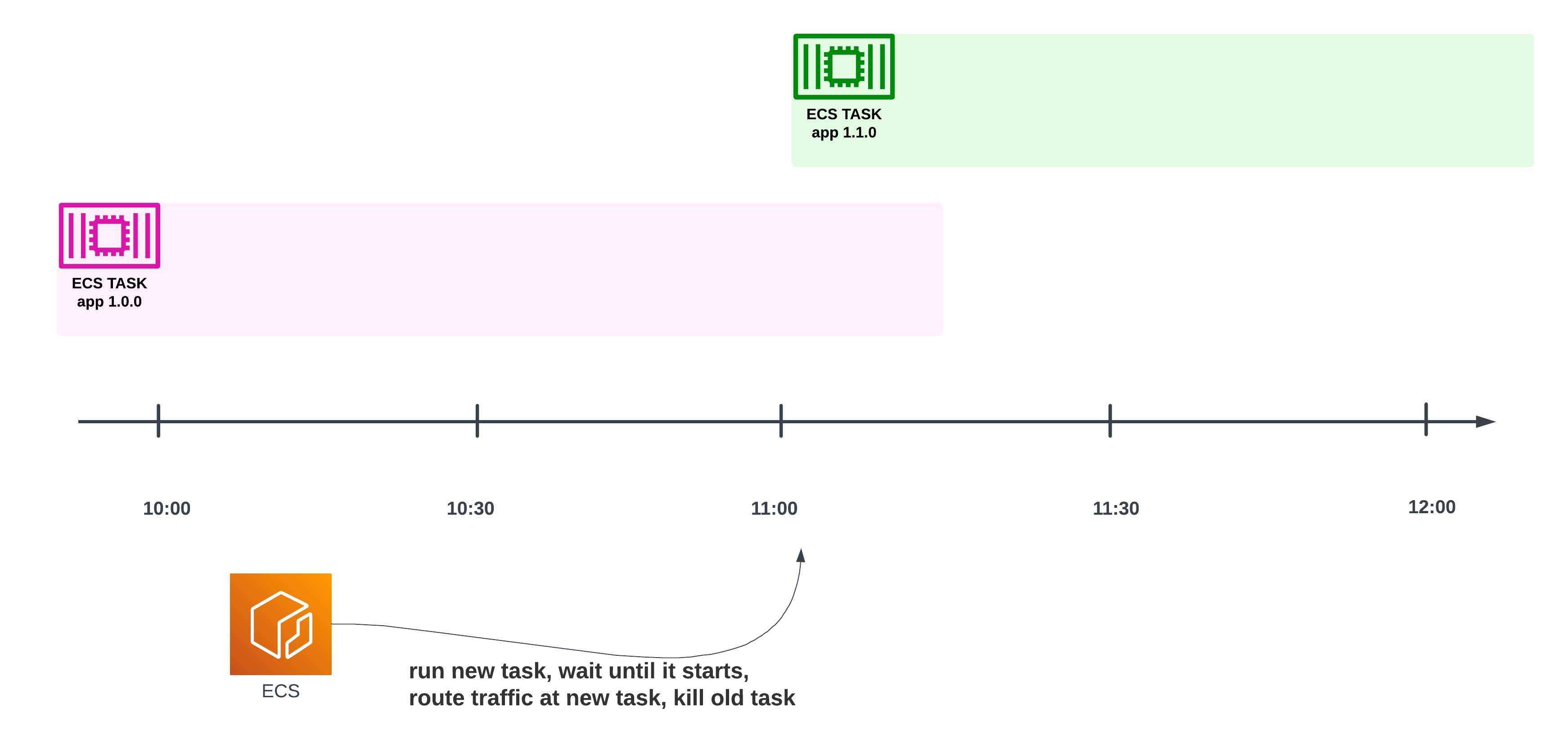
A timeline showing that at some point, the previous version of the container will be shut down and the new version will take over — but with a grace period, letting the old container handle in-flight requests
On the other hand, if the ECS tasks were one-off jobs (like data processing tasks, that are done after processing a chunk of data), then ECS would just run a newer version of the task for the job:
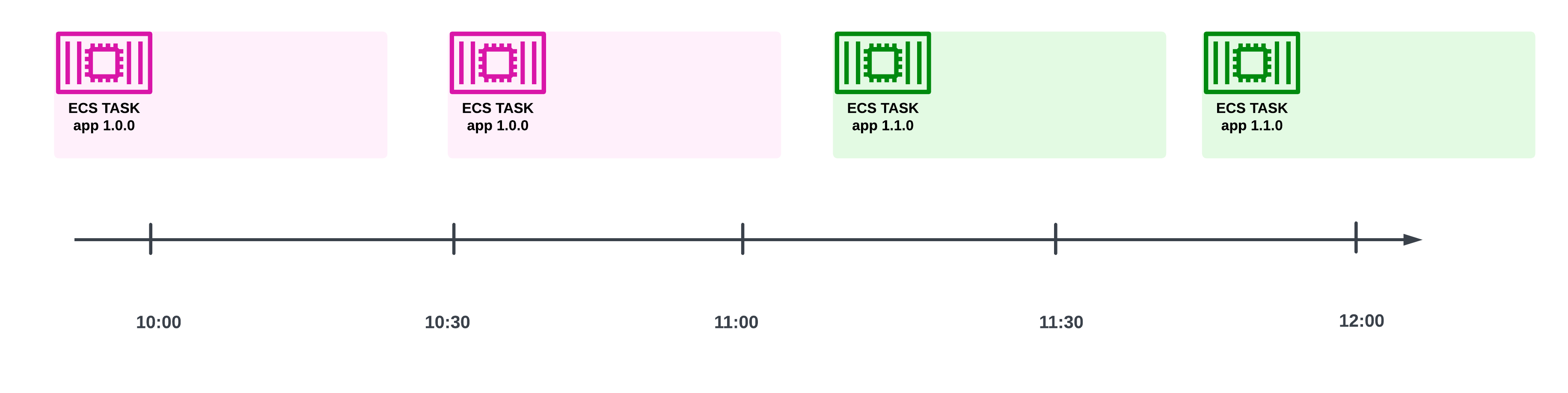
A timeline showing that, starting from some point in time, only new versions of the container will be run
The second scenario is more common in the data engineering world. In data projects, there are often hundreds of one-off tasks running on a schedule. Some tasks produce vital reports for management and other stakeholders. Some process data for machine learning purposes. Some transport data from one place to another, while others monitor the quality of newly ingested data. It looks more or less as follows:
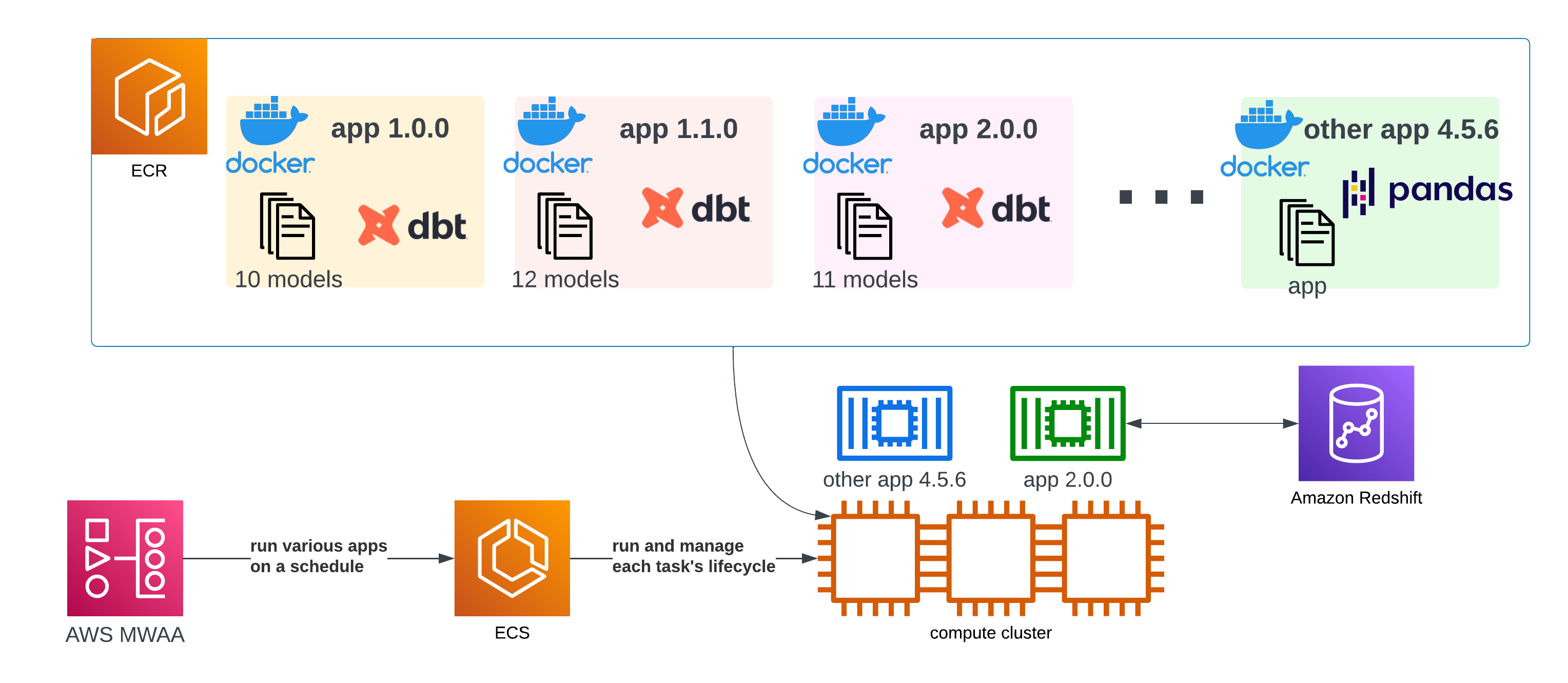
A diagram showing that ECR contains various versions of the containers and MWAA schedules them to run on ECS
There can be dozens of various types of applications, each with their own container and many versions. One of those could contain dbt, itself holding thousands of SQL statements to be scheduled by Amazon Redshift. Alongside, there could be many others, running wildly different software for unrelated purposes.
Their execution graph might end up looking like this:

A timeline showing that at a given moment many different, independent tasks are running at the same time
As workflows tend to increase in number over time and their execution conditions (like the time they are supposed to run at) grow in complexity, it is prudent to set up their scheduling using an existing orchestrator instead of rolling your own.
In this case, we’ll be using AWS MWAA, which is essentially a managed Apache Airflow service neatly integrated with the remainder of AWS’ environment. Besides its core responsibility of scheduling and managing the lifecycle of these tasks, it also keeps track of them, letting us inspect their various logs and metrics in a centralized and clean manner.
While we generally rely on AWS MWAA (Apache Airflow) in our projects, nothing stops you from using different technologies which solve more or less the same problems, such as: AWS Step Functions, Prefect or Mage.
Where’s the catch?
At its core, such a setup is relatively straightforward. However, things can quickly start getting out of hand once we want to run this in multiple environments with a IaC mindset.
First, we need one more ECS “entity” to actually run a container — a Task definition. A Task definition is essentially an extended configuration of a task. At minimum, it defines the container image to run (along with its version), but it can also specify its ports, its CPU and memory limits, its logging configuration — and more.

A diagram showing that to run the ECR container on ECS you also need to create a Task definition revision
Task definitions are immutable and versioned. Each change to a task definition results in a new revision. As such, when you run an ECS task, you tell the ECS service which revision of a Task definition to run — and not which container image and version, as that information is already part of the particular Task definition, at that particular revision.
This adds yet another entity with a versioning scheme to the project. However, you cannot manually adjust said scheme to your liking — their version numbers are simply arbitrary integers. No semantic versioning here.
What’s worse is that in a multi-tenant environment, each account could have their own numbering (for various reasons, like sudden hotfixes at PROD or rapid, manual development at DEV):
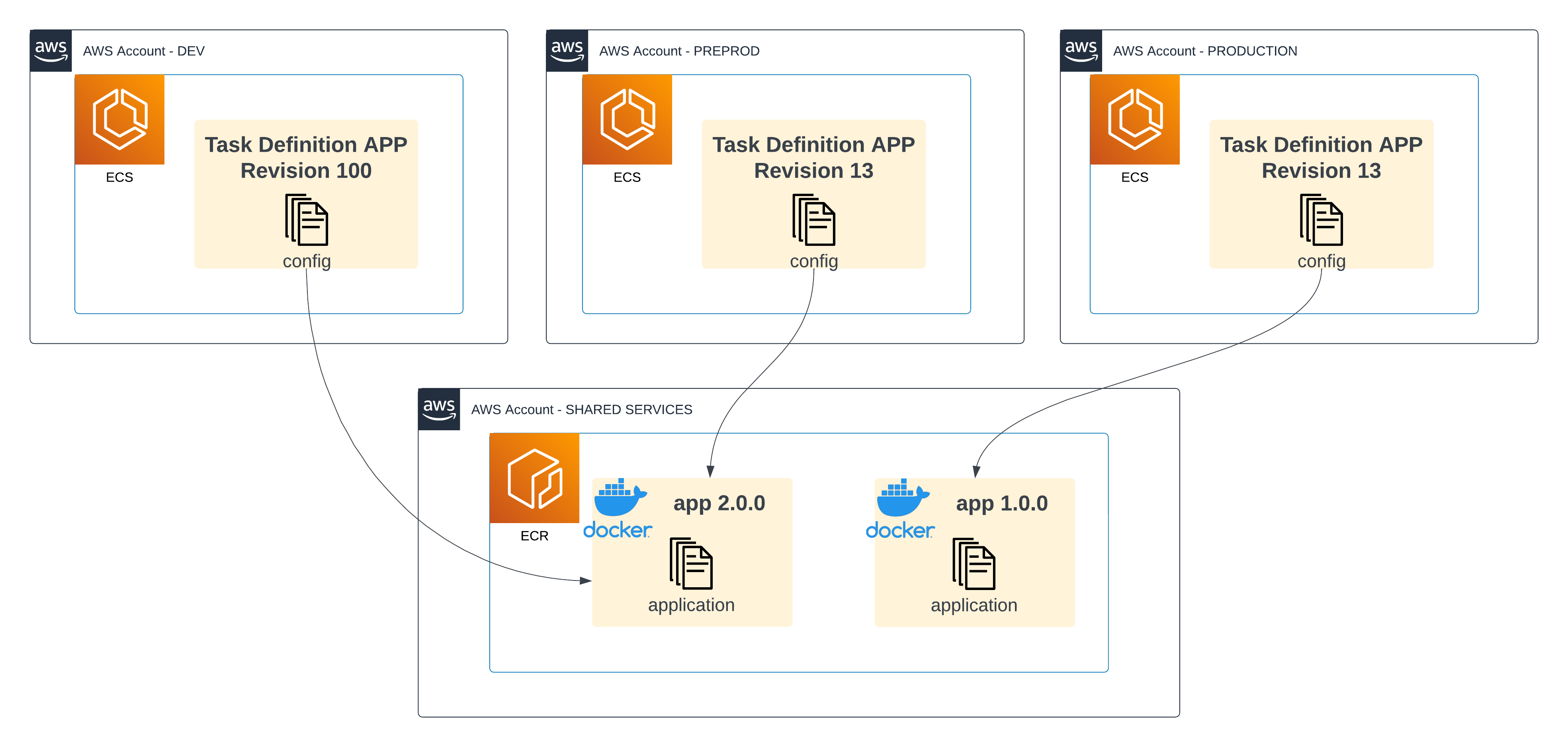
A diagram showing multiple AWS environments (DEV, PREPROD, PRODUCTION) with a mapping between their Task definition revisions to ECR container versions, where ECR is deployed on a Shared Services account. There is a mismatch: revision 13 on PROD targets 1.0.0 and revision 13 on PREPROD targets 2.0.0
Revision 13 at Production could point to version 1.0.0 of the app, while revision 13 at Preprod could target 2.0.0! Whatever schedules these tasks (e.g. MWAA DAGs) needs to take crucial differences into account, forcing you to store potentially wildly different configurations across environments.
On top of that, once IaC tooling is involved (as it should be), when a developer pushes new code — creating a new version of an image in the process — they will also need to tweak IaC setups and wait until those get reviewed and deployed.
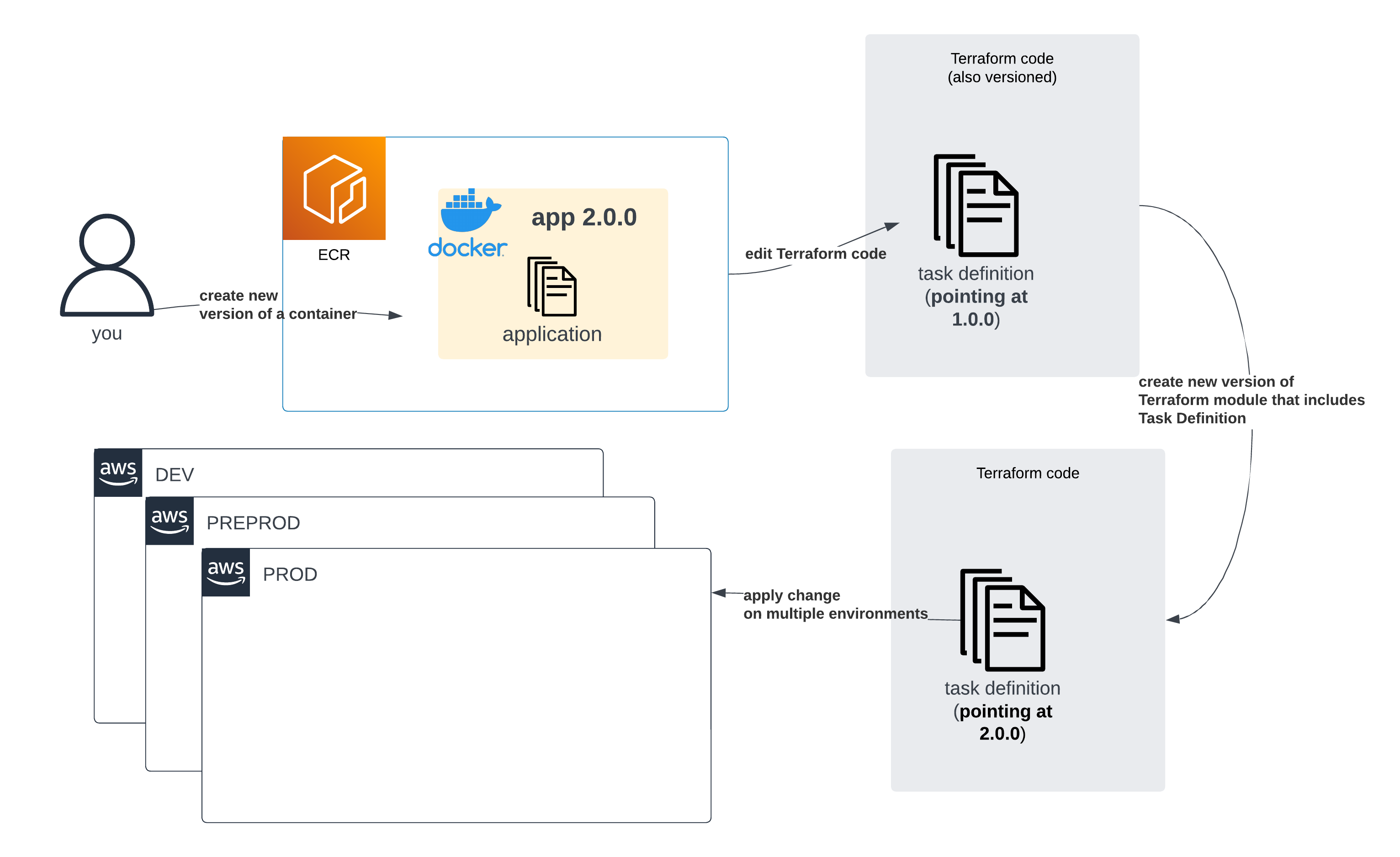
A diagram showing that to create a new version of a Task definition with Terraform, you would first need to release a new module of Terraform with a new version and then deploy it on each of the environments
Woah! Even more cognitive load, more context switching, more complexity! We added a new image version, so we had to deploy a new Terraform module version, to create a new Task definition revision. Great.
This is compounded by the fact that there’s often a separate CI/CD process responsible for the deployment of those tasks (or an orchestrator, such as MWAA, that needs an update in its DAGs to point to a new version), forcing you to ignore some inconsistencies between what’s in your IaC, and what’s really in your system.
To be clear — Task definitions are absolutely necessary in the grand scheme of things. They not only tackle container versioning, but dozens of different configuration parameters. They need their own versioning. However, they are also these weird thingies that reside on the intersection of the application and its infrastructure, instead of firmly in one or the other. Thus, if you try to blindly apply infrastructure practices on them, things start to break at weird places.
Simplifying versioning complexity
In the data engineering domain, a data engineer that just pushed a new SQL statement to their dbt repository and wants to reconfigure Airflow to run it, should be able to do so without all this hassle that we outlined so far:
- Mixing Task definition revisions with IaC is cumbersome;
- Task definition revisions don’t follow semantic versioning rules;
- The version numbering of Task definition revisions varies between environments;
- Data Engineers need to keep track of “which environment runs which version”, which may mean keeping track of DAG version, IaC version, container version and Task definition revision. Dependency hell!
Is there any way we can simplify this flow without sacrificing the benefits those abstractions bring to the table?
We had a simple idea, and it turned out to be the solution: create Task definition revisions on the fly. Create the “piece that connects ECS with the proper container version to run” automatically, at runtime — and only for a single execution.
As a result, your data engineers will only need to remember which container version they want to run. Simple as that.
Dynamically created Task definition revisions
Suppose we need to update our existing app (dbt-model:1.0.0) with new SQL statements. This modification in the dbt-model repository triggers our deployment pipeline — which includes testing — and ultimately results in the creation of a Docker image. This image is then stored in Amazon ECR under the name dbt-model:1.0.1.
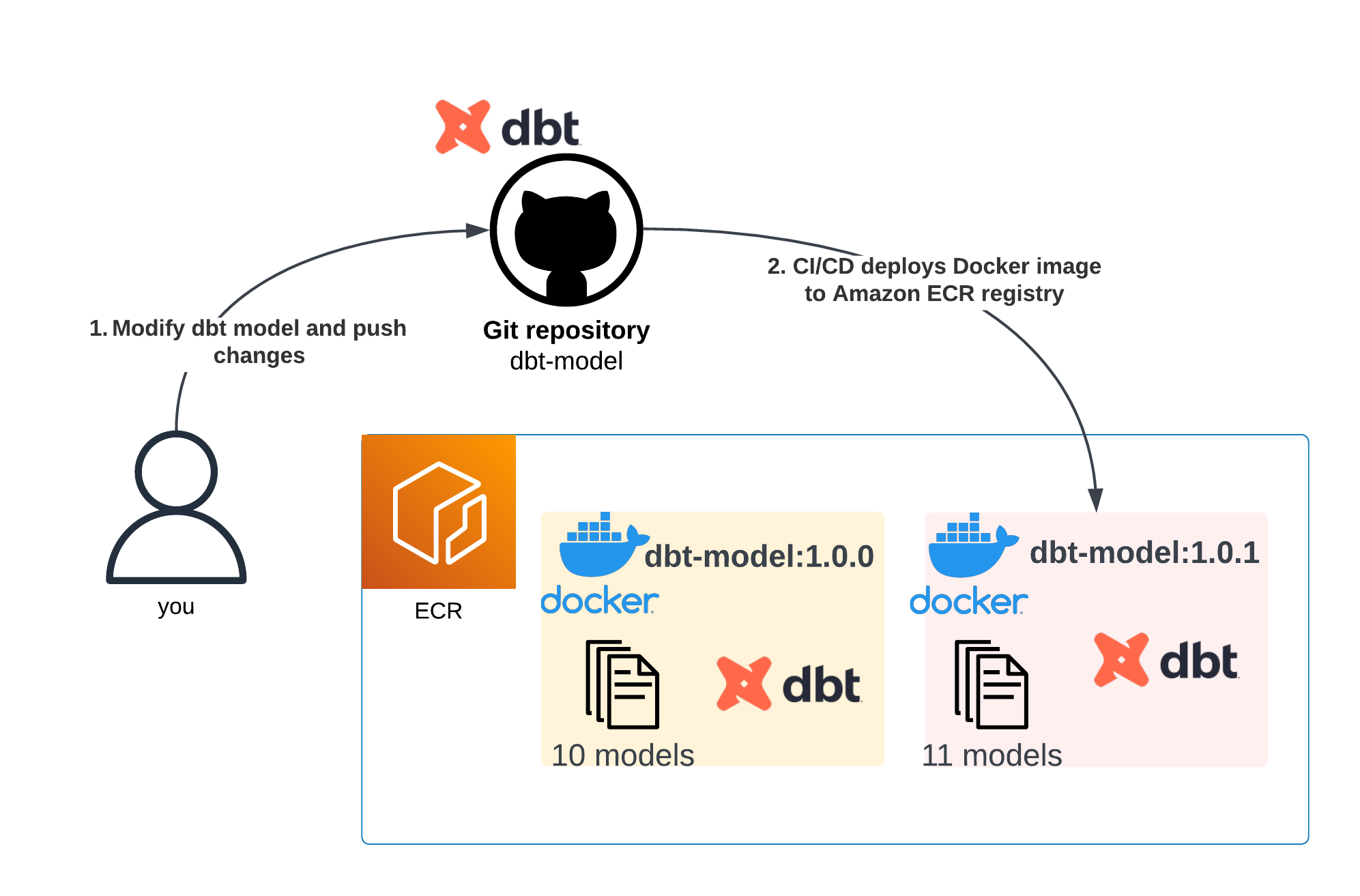
A diagram showing that after a new business feature is created, a new container is automatically built too
Of course, dbt is only an arbitrary example of software that could run in ECS.
In essence, dbt is an orchestrator of SQL statements. It lets you define various data models (“ETLs”) along with their dependencies. Then, dbt connects to your data warehouse and runs them on your behalf. Dbt by itself doesn’t require that much compute power (it uses the compute of the data warehouse), but still needs a place to run in AWS. We utilize ECS for that. However, you can run anything inside your containers — e.g. your own custom Python data processing scripts.
Back to the showcase — once we have the new dbt container image in Amazon ECR, the only action required from the data engineer is to update the reference to point to the image dbt-model:1.0.1 in the Apache Airflow DAG.

A diagram showing that to redeploy a new version of the Airflow DAG you need to modify a specific file, which is watched by CI/CD
So, how exactly is the new revision created?
Here comes the “magic”. A new task definition is created for each DAG execution by using official Amazon ECS Operators for Apache Airflow. Each workflow run leads to the creation of a new Task definition revision, followed by the execution of the dbt code, and ending with its deregistration. With this configuration, the data engineer doesn’t need any prior knowledge about ECS, as the only necessary change is in the dbt model version reference.
See the exact DAG snippet below:
from datetime import datetime, timedeltafrom airflow import DAGfrom airflow.providers.amazon.aws.operators.ecs import (EcsRunTaskOperator,EcsRegisterTaskDefinitionOperator,EcsDeregisterTaskDefinitionOperator)# DBTDBT_MODEL_NAME = "dbt_model"ECR_IMAGE = "XXXXXXXXXXXX.dkr.ecr.amazonaws.com/dbt_model:1.0.1" # <- Model version# ECS Task definition and Cluster configurationTASK_DEFINITION_FAMILY = ""CLUSTER_NAME = ""CONTAINER_NAME = ""# (...)dag = DAG(DBT_MODEL_NAME,default_args=DEFAULT_ARGS,description="A sample DAG to create, run, and deregister an ECS task definition",schedule_interval=timedelta(minutes=30),start_date=datetime.now(),catchup=False)create_ecs_task_definition = EcsRegisterTaskDefinitionOperator(task_id="create_ecs_task_definition",family=TASK_DEFINITION_FAMILY,container_definitions=[{"name": CONTAINER_NAME,"image": ECR_IMAGE,"cpu": CPU,"memory": MEMORY,"portMappings": [],"essential": True,"environment": ENVIRONMENT,"mountPoints": [],"volumesFrom": [],"secrets": SECRETS,"readonlyRootFilesystem": False,"logConfiguration": LOG_CONFIGURATION}],register_task_kwargs={"cpu": str(CPU),"memory": str(MEMORY),"networkMode": "awsvpc","runtimePlatform": {"operatingSystemFamily": "LINUX","cpuArchitecture": "X86_64"},"requiresCompatibilities": ["FARGATE"],"executionRoleArn": EXECUTION_IAM_ROLE,"taskRoleArn": TASK_IAM_ROLE},dag=dag,)run_ecs_task = EcsRunTaskOperator(task_id="run_ecs_task",cluster=CLUSTER_NAME,task_definition="{{ task_instance.xcom_pull(task_ids='create_ecs_task_definition', key='task_definition_arn') }}",launch_type="FARGATE",network_configuration={"awsvpcConfiguration": {"assignPublicIp": "DISABLED","securityGroups": SECURITY_GROUPS,"subnets": SUBNETS}},overrides={"containerOverrides": [{"name": CONTAINER_NAME,"command": ["dbt", "run", "--select", DBT_MODEL_NAME]},],},awslogs_group=LOG_GROUP,awslogs_region="eu-west-1",awslogs_stream_prefix=LOG_STREAM_PREFIX,dag=dag)deregister_ecs_task_definition = EcsDeregisterTaskDefinitionOperator(task_id="deregister_ecs_task_definition",task_definition="{{ task_instance.xcom_pull(task_ids='create_ecs_task_definition', key='task_definition_arn') }}",dag=dag)# Set task dependenciescreate_ecs_task_definition >> run_ecs_task >> deregister_ecs_task_definition
Note that the Task definition contains not just the container version, but also various technical parameters — such as which ECS cluster to run, the security group configuration, and several others. Thankfully, these are mostly static in practice and can be coded once, and then reused.
The screenshot below shows how the DAG execution appears in Apache Airflow’s (MWAA) console:
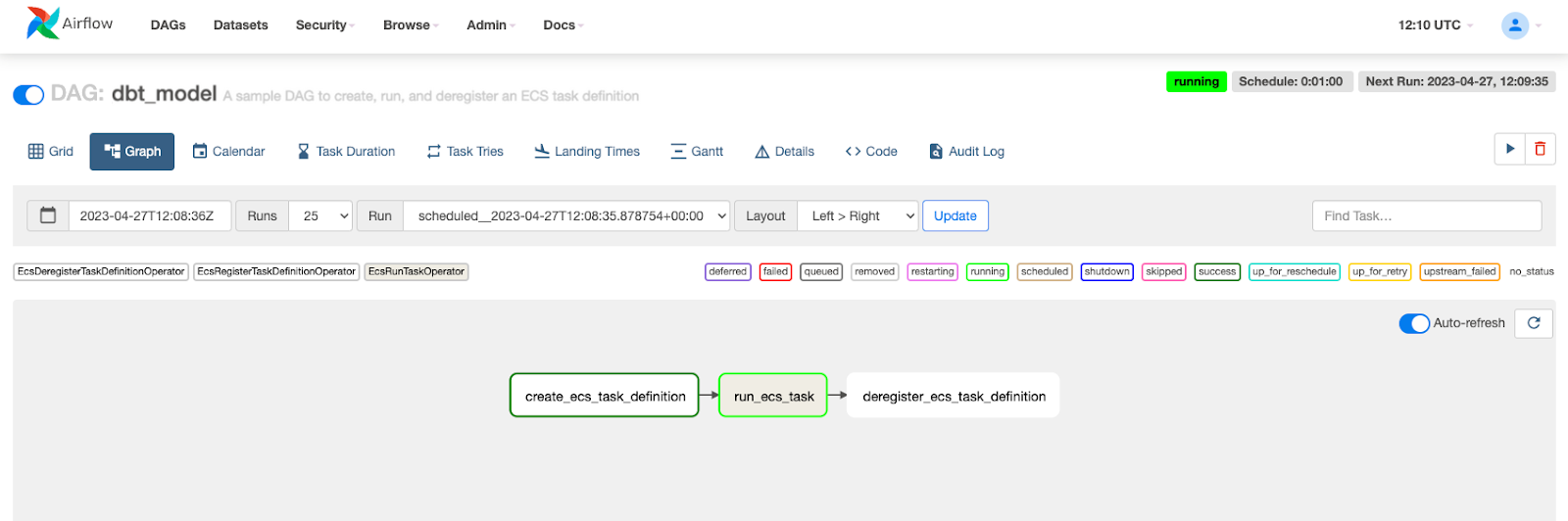
Apache Airflow UI showing three tasks A -> B -> C in a single DAG. The B task (run_ecs_task) runs a dbt container on ECS Fargate
Et voilà.
Your IaC is still used nearly everywhere, but your data team does not need to be aware of all its quirks nor live in dependency hell.
Remember: both AWS MWAA and dbt were used here merely as data engineering-related examples. You could use another orchestrator and other software inside your containers — but the underlying IaC vs Task definition revision issue would still be there… and you could solve it basically the same way we did!
Limits and considerations
Of course, as you run dozens of workflows every day, you might quickly find yourself with thousands of Task definition revisions. AWS imposes a hard limit of 1,000,000 on their count. Deregistering a revision is not the same as deleting it, and does not exclude it from being included in this limit. Still, that’s often enough for years of such practice.
However, if you need more than that, you might want to implement one of the following workarounds:
Lookup table
Reuse existing Task definitions for tasks whenever the Docker image reference and execution configuration remains the same (which could be done by hashing the contents verbatim and simply comparing hashes).
This strategy avoids the creation and deregistration of Task definitions with every run, preventing us from hitting the limit. Instead, we end up creating Task definition devisions only when new image versions are actually generated.
A simple Amazon DynamoDB lookup table can efficiently manage this task, and it also provides a convenient way to maintain an audit trail and historical records.
Automatically delete old Task definition revisions
Introduce a periodic clean-up process to remove old, unused Task definition revisions. This practice keeps the total count of revisions comfortably below the upper limit, ensuring the availability of room for creating new ones as needed.
For instance, this process could be configured to remove all inactive Task definition revisions older than six months.
Summary
Scheduling and managing ephemeral tasks on AWS is simple and efficient with technologies such as AWS ECS and AWS MWAA. However, as you add more environments and IaC to the mix, the subtle quirks of Task definition revisions might complicate your life.
Thankfully, you can simply detach the Task definition revisions from your IaC setup altogether, and just generate them at runtime — saving you many headaches and sleepless nights.
