Streaming DynamoDB changes to SQS with Lambda
Exploring the usefulness and rough edges of Amazon DynamoDB Streams, using AWS Lambda to stream changes to SQS in real-time.
 Amazon DynamoDB
Amazon DynamoDB Amazon SQS
Amazon SQS AWS Lambda
AWS Lambda Serverless Framework
Serverless Framework

Sooner or later in any development process based on serverless architecture in AWS, you’re going to come across DynamoDB streams. If you’re already familiar with event-based development patterns, then DynamoDB Streams can seem like an easy way to capture DynamoDB activity and use it to invoke further actions.
However, the devil is in the details — and in this case those might cost you unnecessary money. So, let’s not waste time and set a stream, attach a Lambda function to it and highlight those details.
The basics of DynamoDB Streams
AWS maintains separate endpoints for DynamoDB and DynamoDB Streams. To work with database tables and indexes, the application must access a DynamoDB endpoint. However, if you want to process DynamoDB Streams records, your request must obtain a DynamoDB Streams endpoint in the same Region.
A stream consists of stream records. Each stream record represents a single data change in the DynamoDB table to which the flow belongs. Each stream record is assigned a sequence number, reflecting the order in which the record was published to the stream.
Depending on the operation that was performed on the DynamoDB table, the application will receive a corresponding INSERT, MODIFY, or REMOVE event:
{"Records": [{"eventID": "1","eventName": "INSERT","eventVersion": "1.0","eventSource": "aws:dynamodb","awsRegion": "us-east-1","dynamodb": {"Keys": {"Id": {"N": "101"}},"NewImage": {"Message": {"S": "New item!"},"Id": {"N": "101"}},"SequenceNumber": "111","SizeBytes": 26,"StreamViewType": "NEW_AND_OLD_IMAGES"},"eventSourceARN": "stream-ARN"}, {"eventID": "2","eventName": "MODIFY","eventVersion": "1.0","eventSource": "aws:dynamodb","awsRegion": "us-east-1","dynamodb": {"Keys": {"Id": {"N": "101"}},"NewImage": {"Message": {"S": "This item has changed"},"Id": {"N": "101"}},"OldImage": {"Message": {"S": "New item!"},"Id": {"N": "101"}},"SequenceNumber": "222","SizeBytes": 59,"StreamViewType": "NEW_AND_OLD_IMAGES"},"eventSourceARN": "stream-ARN"}, {"eventID": "3","eventName": "REMOVE","eventVersion": "1.0","eventSource": "aws:dynamodb","awsRegion": "us-east-1","dynamodb": {"Keys": {"Id": {"N": "101"}},"OldImage": {"Message": {"S": "This item has changed"},"Id": {"N": "101"}},"SequenceNumber": "333","SizeBytes": 38,"StreamViewType": "NEW_AND_OLD_IMAGES"},"eventSourceARN": "stream-ARN"}]}
Stream records are organized into groups or shards. Each shard acts as a container for multiple stream records and contains the information required for accessing and iterating through these records.
Creating a DynamoDB Stream
Using the Serverless Framework, the simplest way to define DynamoDB Streams is alongside your database in the Resource section of serverless.yml.
Normally, I prefer to separate everything — apart from function definitions — into dedicated .yml files and reference them via ${file({your_file_name}.yml)} instead, to keep everything neatly organized.
Resources:AnalysisMetadataTable:Type: AWS::DynamoDB::TableProperties:TableName: ${self:custom.analysis-tablename}AttributeDefinitions:- AttributeName: analysisRequestIdAttributeType: S- AttributeName: requestorIdAttributeType: SKeySchema:- AttributeName: analysisRequestIdKeyType: HASHStreamSpecification:StreamViewType: NEW_IMAGEProvisionedThroughput:ReadCapacityUnits: 10WriteCapacityUnits: 10GlobalSecondaryIndexes:- IndexName: requestorId-gsiKeySchema:- AttributeName: requestorIdKeyType: HASHProjection:ProjectionType: ALLProvisionedThroughput:ReadCapacityUnits: 5WriteCapacityUnits: 5Tags:- Key: NameValue: ${self:custom.analysis-tablename}- Key: EnvironmentValue: ${self:custom.stage}- Key: ProjectValue: ${self:custom.app}- Key: ApplicationValue: ${self:custom.service_acronym}
StreamSpecification defines how the stream is configured. You’ve got four options in terms of the type of information that will be written to the stream whenever data in the table is modified:
KEYS_ONLY— Only the key attributes of the modified item.NEW_IMAGE— The entire item, as it appears after it was modified.OLD_IMAGE— The entire item, as it appeared before it was modified.NEW_AND_OLD_IMAGES— Both the new and the old images of the item.
I chose NEW_IMAGE, but that’s not all we need.
Binding a Lambda to a DynamoDB Stream
The next step is to define the Lambda function responsible for collecting and processing the data from the stream.
First, we have to attach an IAM Role with the right permissions to manage resources related to our DynamoDB Streams. We’re going to need:
Action:- dynamodb:DescribeStream- dynamodb:GetRecords- dynamodb:GetShardIterator- dynamodb:ListStreams
Then, as the resource we’re setting the ARN of the stream:
arn:aws:dynamodb:{REGION}:{ACCOUNT_ID}:table/{TABLE_NAME}/stream/{STREAM}And the full IAM Role resource could then be defined like this:
Resources:StreamProcessorRole:Type: AWS::IAM::RoleProperties:AssumeRolePolicyDocument:Version: "2012-10-17"Statement:- Effect: AllowPrincipal:Service:- lambda.amazonaws.comAction:- sts:AssumeRolePath: /Policies:- PolicyName: metadata-stream-processor-${self:custom.stage}PolicyDocument:Version: "2012-10-17"Statement:- Effect: AllowAction:- dynamodb:DescribeStream- dynamodb:GetRecords- dynamodb:GetShardIterator- dynamodb:ListStreamsResource:- arn:aws:dynamodb:#{AWS::Region}:#{AWS::AccountId}:table/${self:custom.analysis-tablename}/stream/*
[!CAUTION] I’ve used * as STREAM in the ARN because you cannot describe the stream unless it’s created. Of course, to maintain the principle of least privilege, you should limit the IAM Role only to the stream you are going to create.
When using the Serverless Framework, the first problem you’re going to encounter integrating your Lambda function is actually defining the stream as an event for Lambda. Take a look at the example function I’ve been using for processing the stream data.
We’ve got an events section, wherein we define the DynamoDB Stream as a source event for our Lambda function:
events:- stream:type: dynamodbarn:Fn::GetAtt:- AnalysisMetadataTable- StreamArnbatchSize: 10startingPosition: LATESTenabled: True
The issue is that it doesn’t bind the source event to the Lambda function. To do that you have to first create a stream for DynamoDB…
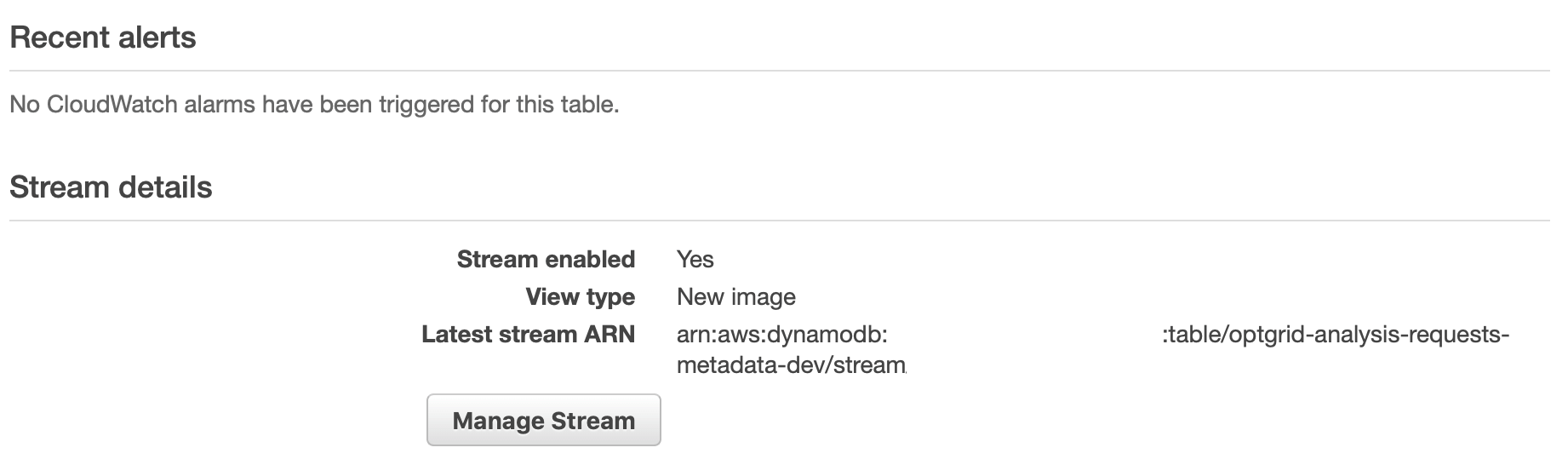
AWS Console showing a created DynamoDB Stream and its ARN.
… and after it is visible in the console — or via the describe_stream() method of DynamoDBStreams available in boto3 — you must then define another stream in the events section…
- stream: arn:aws:dynamodb:#{AWS::Region}:#{AWS::AccountId}:table/${self:custom.analysis-tablename}/stream/{STREAM}… with STREAM replaced with the proper key, of course.
Finally, after the stack gets rebuilt with sls deploy, you should see your event source trigger attached to the particular Lambda function, you’ve added it for:
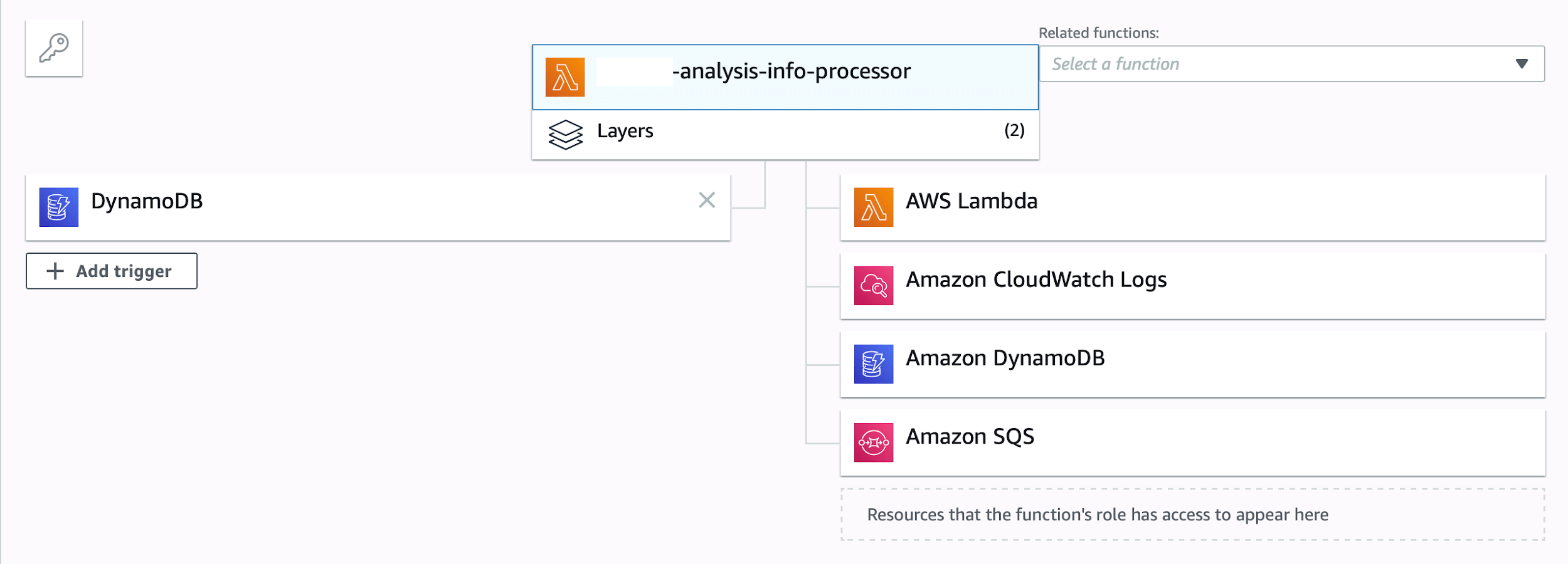
AWS Console showing DynamoDB as an event source trigger for AWS Lambda.
Here’s the full configuration of the Lambda function including those changes:
analysis-info-processor:name: ${self:custom.app}-${self:custom.service_acronym}-analysis-info-processordescription: Handles a DynamoDB stream and queues data in SQS for an analysis workerhandler: functions.analysis_metadata_processor.lambda_handlerrole: StreamProcessorRoleruntime: python3.6reservedConcurrency: 50alarms: # Merged with function alarms- functionErrorsdeadLetter:sqs: # New Queue with these propertiesqueueName: ${self:custom.analysis-info-processor-dlq}delaySeconds: 10maximumMessageSize: 2048messageRetentionPeriod: 86400receiveMessageWaitTimeSeconds: 5visibilityTimeout: 300environment:tablename: ${self:custom.analysis-tablename}tags:Name: ${self:custom.app}-${self:custom.service_acronym}-analysis-info-processorlayers:- arn:aws:lambda:${self:provider.region}:#{AWS::AccountId}:layer:aws-custom-logging-${self:custom.stage}:${self:custom.logging-layer-version}events:- stream: arn:aws:dynamodb:#{AWS::Region}:#{AWS::AccountId}:table/${self:custom.analysis-tablename}/stream/{STREAM}- stream:type: dynamodbarn:Fn::GetAtt:- AnalysisMetadataTable- StreamArnbatchSize: 10startingPosition: LATESTenabled: True
Watch out for processing errors
Lambda reads records from the stream and invokes your function synchronously with the event that contains stream records. Generally Lambda polls shards in your DynamoDB Streams for records at a base rate of 4 times per second. When new records are available, Lambda invokes your function and waits for the result.
- If processing succeeds, Lambda resumes polling until it receives more records.
- If your function returns an error, Lambda retries the batch until processing succeeds or the data expires — which means errors might get costly, because the Lambda will be repeatedly invoked until either condition is true.
Learn from my mistake:
for record in event['Records']:if record['eventName'] == 'MODIFY' and record['dynamodb']['NewImage']['phase']['S'] == 'FILE_UPLOAD_COMPLETE':
Here, among all received records I was looking for MODIFY events (eventName) which are in the FILE_UPLOAD_COMPLETE.
This did get costly for me once I filled the table with testing data, and DynamoDB started to pass it to my Lambda function. Unfortunately, because of my mistake, my code didn’t process the stream data properly and kept returning an error… that I didn’t get notified about (alarm not configured). The stream kept silently invoking my function during the night, and I only realized it the next day.
Twenty-four hours of data retention might be either great — or like in my case: a costly lesson to remember.
Batch when possible
By default, Lambda invokes your function as soon as records are available in the stream. If the batch it reads from the stream only has one record in it, Lambda only sends one record to the function. To avoid invoking the function inefficiently with a small number of records, you can tell the event source to buffer records for up to 5 minutes by configuring a batch window. Before invoking the function, Lambda continues to read records from the stream until it has gathered a full batch, or until the batch window expires.
With the Serverless Framework, you can specify these parameters when defining your events:
- Batch size — The number of records to read from a shard in each batch, up to 1,000. Lambda passes all the records in the batch to the function in a single call, as long as the total size of the events doesn’t exceed the payload limit for synchronous invocation (6 MB).
- Batch window — Specify the maximum amount of time to gather records before invoking the function, in seconds.
- Starting position — Process only new records, or all existing records.
- Latest — Process new records added to the stream.
- Trim horizon — Process all records in the stream.
events:- stream: arn:aws:dynamodb:#{AWS::Region}:#{AWS::AccountId}:table/${self:custom.analysis-tablename}/stream/{YOUR_STREAM}- stream:type: dynamodbarn:Fn::GetAtt:- AnalysisMetadataTable- StreamArnbatchSize: 10startingPosition: LATESTenabled: True
Your Lambda function will be invoked when one of the following three things happens:
- The total payload size reaches 6MB;
- The
batchWindow(not configured in my example) reaches its maximum value; - The
batchSizereaches its maximum value.
But, there is always a catch when processing more than a single record. A Lambda function cannot tell the DynamoDB Stream, Hey, I just successfully processed these 10 events you sent me, but these 10 unfortunately failed, so please retry sending me only those 10 that failed
. If you fail in the Lambda function, the DynamoDB stream will resend the entire batch again.
What I don’t recommend is to set your batchSize to 1, because the ability to process a greater number of events at once is a huge performance benefit. However, there’s no silver bullet to handling errors, so be aware of issues that might occur with batch sizes greater than 1.
Conclusion
Besides our practical introduction to consuming DynamoDB Streams, there are two primary takeaways from this article:
- If your function returns an error, Lambda retries the batch until processing succeeds or the data expires — do not forget about that as I did.
- If you merely partially succeed processing a batch, keep in mind that you cannot rerequest only the records that failed. Generally, that’s a little bit problematic e.g. if you have already written part of your data to a table. Contrary to the DynamoDB stream in SQS, which allows you to delete a single message from the queue, so it does not get processed again. Removing a record in DynamoDB streams is not possible, because it doesn’t track how its consumers are reading the events to begin with.
